

카프카로부터 받은 로그 메시지를 S3에 업로드하는 애플리케이션
카프카를 이용한 로그 전송 애플리케이션 구현: Spring Boot, Kafka
지난 글에서는 카프카를 이용하여 로그 메시지를 전송하는 애플리케이션을 구현했습니다.
이번 글에서는 카프카로부터 로그 메시지를 받아 파일로 저장한 후, 이를 AWS S3에 업로드하는 Spring Boot 애플리케이션을 구현하겠습니다.
실습 소스코드
Github 실습 레포: spring-logging-with-kafka > LogtoS3 폴더 참고
GitHub - Autoever-mobility-cloud-school/spring-logging-with-kafka: Spring Boot와 Kafka를 이용한 로깅 애플리케이션
Spring Boot와 Kafka를 이용한 로깅 애플리케이션. Contribute to Autoever-mobility-cloud-school/spring-logging-with-kafka development by creating an account on GitHub.
github.com
애플리케이션 아키텍처
1. 프로젝트 설정
프로젝트 생성
로그를 전송하는 애플리케이션과 동일한 의존성을 가진 Spring Boot 프로젝트를 생성한다.
Dependencies
Spring Web
Spring DevTools
Lombok
Spring for Apache Kafka
application.yaml 파일 작성
앞에서 만들었던 로그를 전송하는 애플리케이션이 8080번 포트를 사용하기 때문에, 여기서는 포트를 8081번을 사용하도록 설정하였다.
spring.kafka.bootstrap-servers에서 <public-ip>에는 EC2 인스턴스의 퍼블릭 IP를 넣으면 된다. (<> 제거)
server:
port: 8081
spring:
kafka:
bootstrap-servers: <public-ip>:9092
consumer:
group-id: itstudy
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer2. Kafka 메시지 처리
1) Kafka 환경 설정 클래스
Kafka 설정은 별도의 KafkaConfiguration.java에서 정의하여 재사용한다.
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaConfiguration {
//application.properties 나 application.yaml 파일에 있는
//키의 값을 가져와서 설정
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public ProducerFactory<String, String> producerFactory(){
Map<String, Object> configs = new HashMap<>();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory(configs);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate(){
return new KafkaTemplate<>(producerFactory());
}
}
2) Kafka 메시지 소비 클래스
카프카로부터 메시지를 수신하고 파일로 저장한 뒤, 이를 S3에 업로드하는 기능을 구현한다:
토픽으로부터 메시지를 읽어오는 클래스: KafkaConsumer.java
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
@Service
public class KafkaConsumer {
@KafkaListener(topics="log-topic",groupId="itstudy")
public void listen(String message) throws Exception {
System.out.println(message);
String filename = "log.txt";
File file = new File(filename);
FileWriter writer = new FileWriter(file, true);
writer.write(message);
writer.close();
}
}3. AWS S3 설정
1) IAM 사용자 생성
외부에서 S3 버킷을 사용하고자 하면 버킷 사용 권한을 가진 사용자의 키가 필요하다.
AWS 관리 콘솔 > IAM 사용자 생성 & 액세스 키 생성
- AWS 콘솔에서 IAM 사용자를 생성하고 액세스 키를 발급받는다.
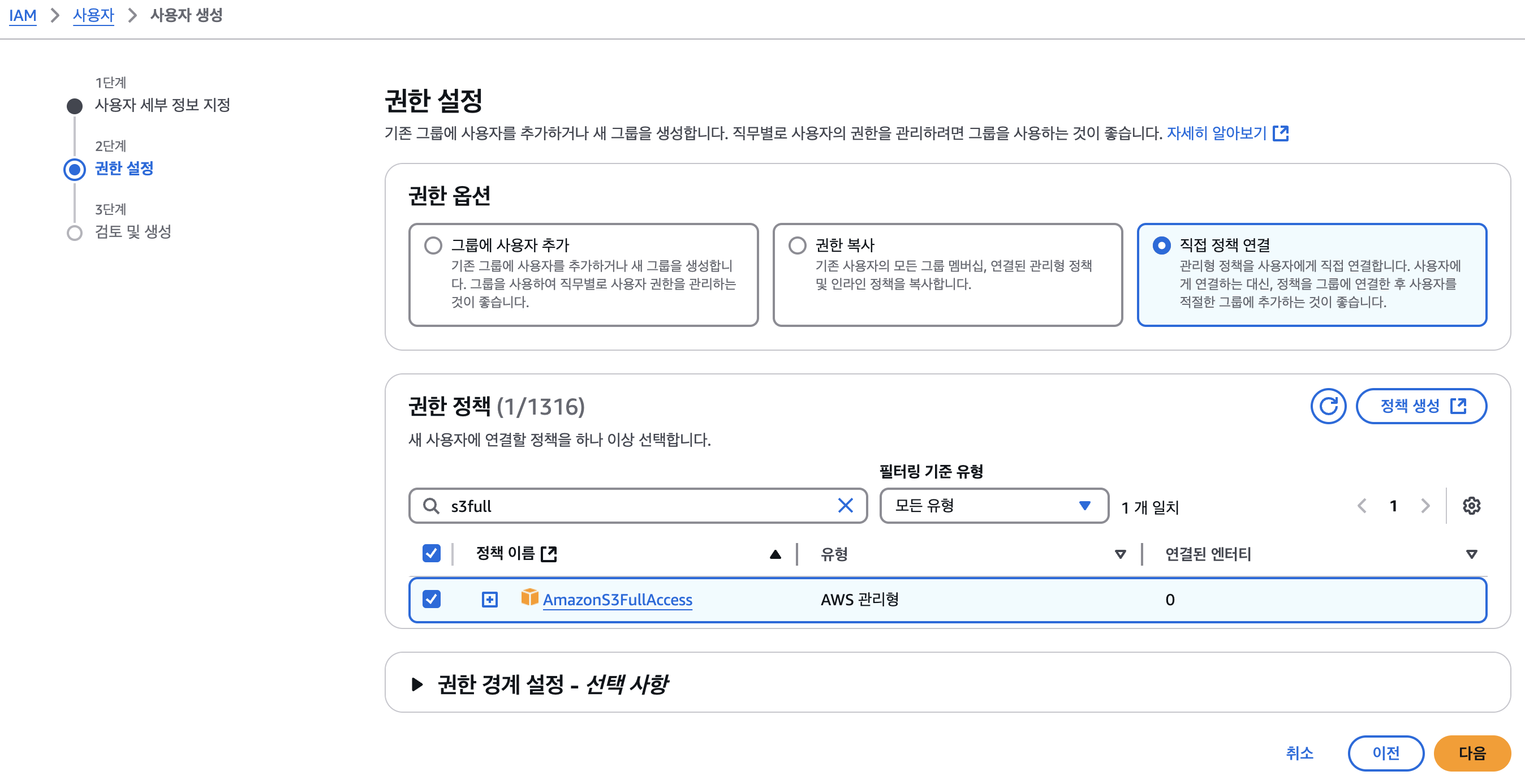
- S3FullAccess 정책을 연결하여 S3 접근 권한을 부여한다.
- 정책 연결: S3FullAccess 권한
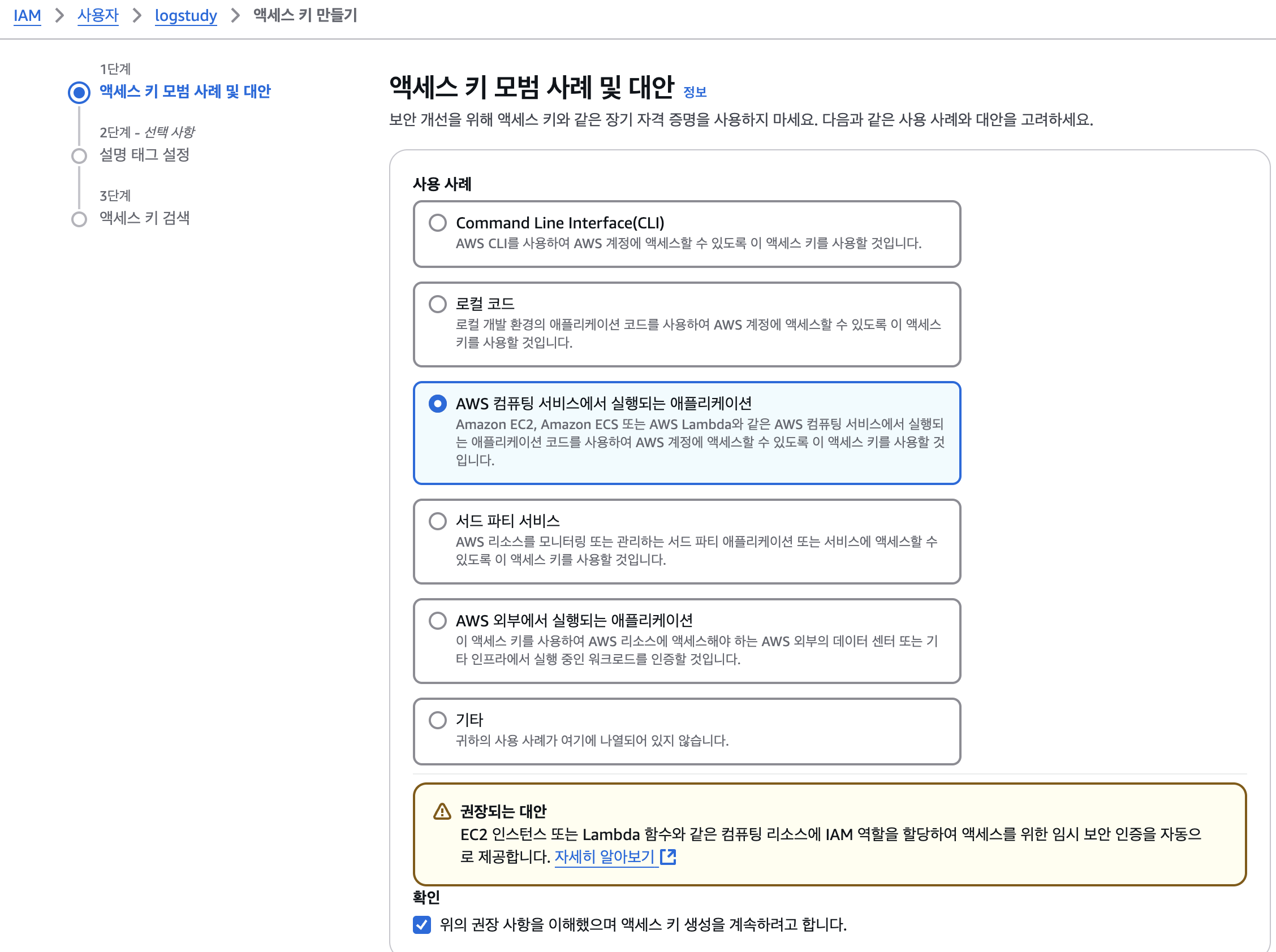
액세스 키 만들기
사용자 > 보안 자격 증명 > 액세스 키 만들기
Access Key를 발급받아서 로컬 컴퓨터에 저장한다.
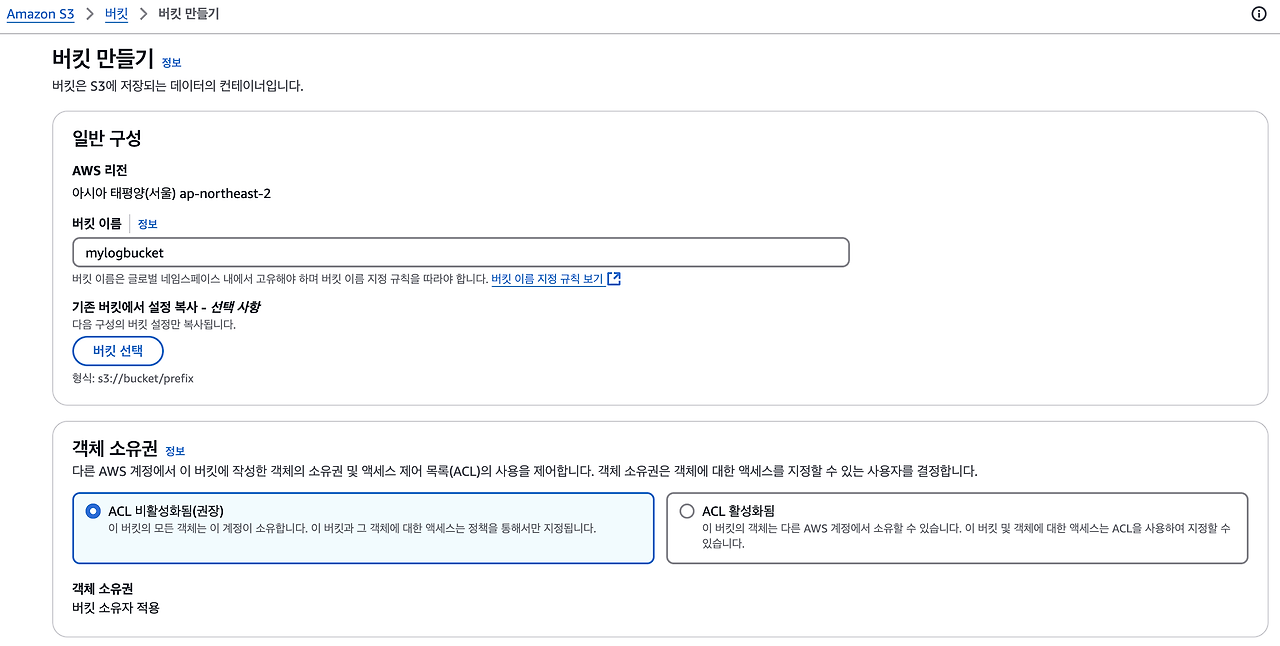
2) S3 버킷 생성
버킷을 생성할 때 public access가 가능하도록 설정하고, 필요한 권한을 설정한다.
참고: [AWS] S3에 React 프로젝트 배포하기: 정적 웹 호스팅, CORS 설정
[AWS] S3에 React 프로젝트 배포하기: 정적 웹 호스팅, CORS 설정
S3에 React 프로젝트 배포하기깃허브 실습 레포:https://github.com/bestlalala/cloudschool-web.git이번 실습 과제에서는 백엔드 코드는 ECS에 배포하고, React.js로 만든 프론트엔드 코드는 S3에 정적 웹으로 배
ynslee627.tistory.com
- 객체 소유권: ACL 비활성화됨.
- 버킷의 퍼블릭 액세스 차단 해제


버킷의 권한 수정
버킷 정책 편집에서 버킷 정책을 작성해준다.
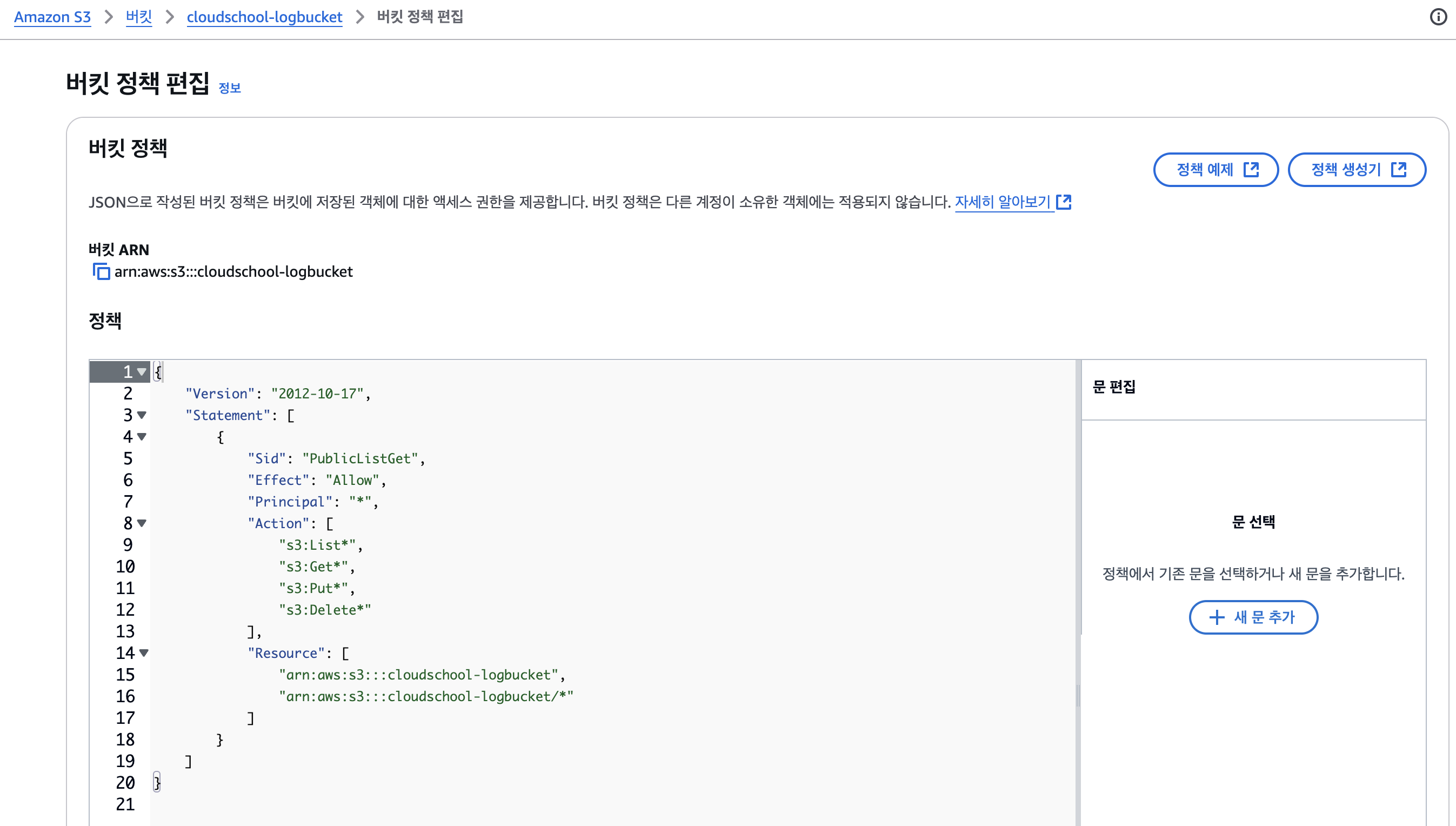
다음과 같이 작성하되, Resource에서 버킷 ARN을 자신의 버킷에 맞게 수정한다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicListGet",
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:List*",
"s3:Get*",
"s3:Put*",
"s3:Delete*"
],
"Resource": [
"arn:aws:s3:::<버킷이름>",
"arn:aws:s3:::<버킷이름>/*"
]
}
]
}4. S3 사용을 위한 설정
1) 의존성 추가
build.gradle에 AWS S3 사용을 위한 의존성을 추가한다:
implementation 'io.awspring.cloud:spring-cloud-starter-aws:2.3.1'
2) application.yaml 파일 수정
파일을 업로드할 프로젝트의 application.yml 파일에 S3 버킷에 대한 설정을 추가한다.
여기서, 액세스키는 외부에 공개되면 안 되기 때문에, .env 파일을 따로 만들어서 설정해주었다.
참고: [Spring] 스프링부트 환경변수 설정 방법: .env, dotenv 없이, application-test.yaml
cloud:
aws:
credentials:
access-key: ${ACCESS_KEY}
secret-key: ${SECRET_KEY}
s3:
bucket: ${S3_BUCKET_NAME}
region:
static: ap-northeast-2
stack:
auto: false전체 코드
server:
port: 8081
spring:
config:
import: optional:file:.env[.properties]
kafka:
bootstrap-servers: <public-ip>:9092
consumer:
group-id: itstudy
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
cloud:
aws:
credentials:
access-key: ${ACCESS_KEY}
secret-key: ${SECRET_KEY}
s3:
bucket: ${S3_BUCKET_NAME}
region:
static: ap-northeast-2
stack:
auto: false
3) 파일 이름 관리
파일 업로드 시 이름 중복을 방지하기 위해 유틸리티 클래스를 작성한다: CommonUtils 클래스 생성
public class CommonUtils {
private static final String EXETENSION_SEPERATOR = ".";
private static final String TIME_SEPERATOR = "_";
//원본 파일을 가지고 실제 업로드되는 파일 이름을 만들어주는 메서드
public static String fileNameCreate(String fileName){
int extensionIndex = fileName.lastIndexOf(EXETENSION_SEPERATOR);
String fileExtension = fileName.substring(extensionIndex);
String uploadName = fileName.substring(0, extensionIndex);
String now = String.valueOf(System.currentTimeMillis());
StringBuilder sb = new StringBuilder(uploadName)
.append(TIME_SEPERATOR)
.append(now)
.append(fileExtension);
return sb.toString();
}
}
4) 로그파일을 S3 버킷에 업로드
KafkaConsumer 수정
카프카로부터 수신한 메시지를 파일로 만들어서 S3 버킷에 업로드하는 코드를 추가한다.
import com.amazonaws.auth.AWSCredentials;
import com.amazonaws.auth.AWSStaticCredentialsProvider;
import com.amazonaws.auth.BasicAWSCredentials;
import com.amazonaws.services.s3.AmazonS3;
import com.amazonaws.services.s3.AmazonS3ClientBuilder;
import com.amazonaws.services.s3.model.CannedAccessControlList;
import com.amazonaws.services.s3.model.ObjectMetadata;
import com.amazonaws.services.s3.model.PutObjectRequest;
import jakarta.annotation.PostConstruct;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
import java.io.*;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
@Service
@Slf4j
public class KafkaConsumer {
private AmazonS3 amazonS3;
@Value("${cloud.aws.credentials.access-key}")
private String accessKey;
@Value("${cloud.aws.credentials.secret-key}")
private String secretKey;
@Value("${cloud.aws.s3.bucket}")
private String bucketName;
@Value("${cloud.aws.region.static}")
private String region;
@Value("${logging.file.path}")
private String logFilePath;
@PostConstruct
public void setS3Client() {
AWSCredentials credentials = new BasicAWSCredentials(accessKey, secretKey);
amazonS3 = AmazonS3ClientBuilder.standard()
.withCredentials(new AWSStaticCredentialsProvider(credentials))
.withRegion(region)
.build();
}
@KafkaListener(topics="log-topic",groupId="itstudy")
public void listen(String message) throws Exception {
log.info(message);
try {
// 메시지를 로그 파일에 추가
File logFile = new File(logFilePath);
try (FileWriter writer = new FileWriter(logFile, true)) {
writer.write(message + System.lineSeparator());
}
// 로그 파일을 S3에 업로드
uploadFileToS3(logFile);
} catch (Exception e) {
log.error("Error processing Kafka message", e);
}
}
private void uploadFileToS3(File file) {
try {
String s3FileName = CommonUtils.fileNameCreate(file.getName()); // 파일명 생성
// ContentType 설정
Path source = Paths.get(file.getAbsolutePath());
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentType(Files.probeContentType(source));
metadata.setContentLength(file.length());
try (InputStream inputStream = new FileInputStream(file)) {
amazonS3.putObject(new PutObjectRequest(bucketName, s3FileName, inputStream, metadata)
.withCannedAcl(CannedAccessControlList.Private)); // 액세스 권한 설정
}
log.info("File uploaded to S3: {}", s3FileName);
} catch (Exception e) {
log.error("Error uploading file to S3", e);
}
}
}
애플리케이션 실행 및 확인
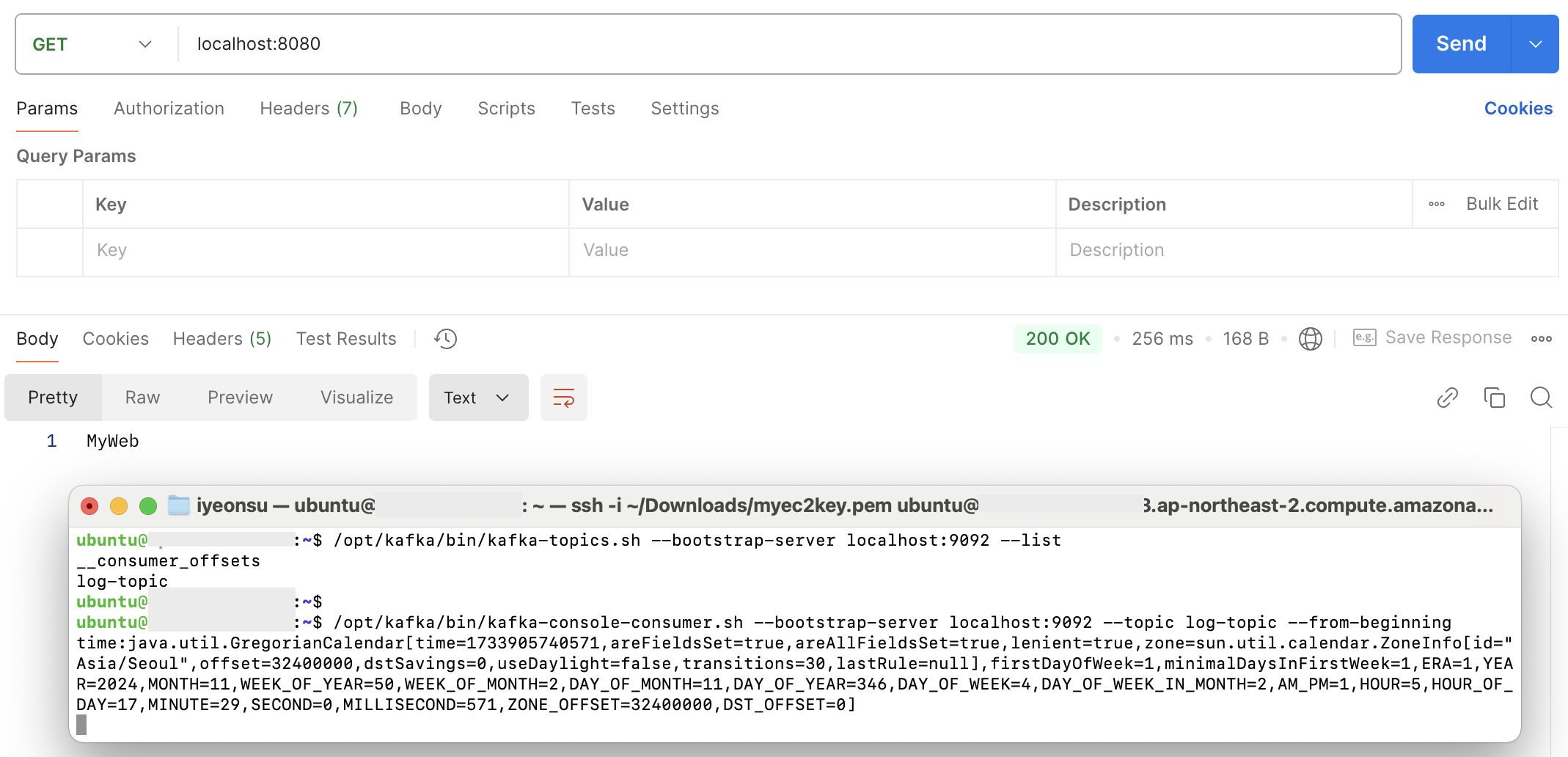
로그에서 S3에 로그 파일을 업로드했다는 메시지를 확인할 수 있다!

S3 버킷을 확인해보면, 로그파일이 업로드된 것을 확인할 수 있다.
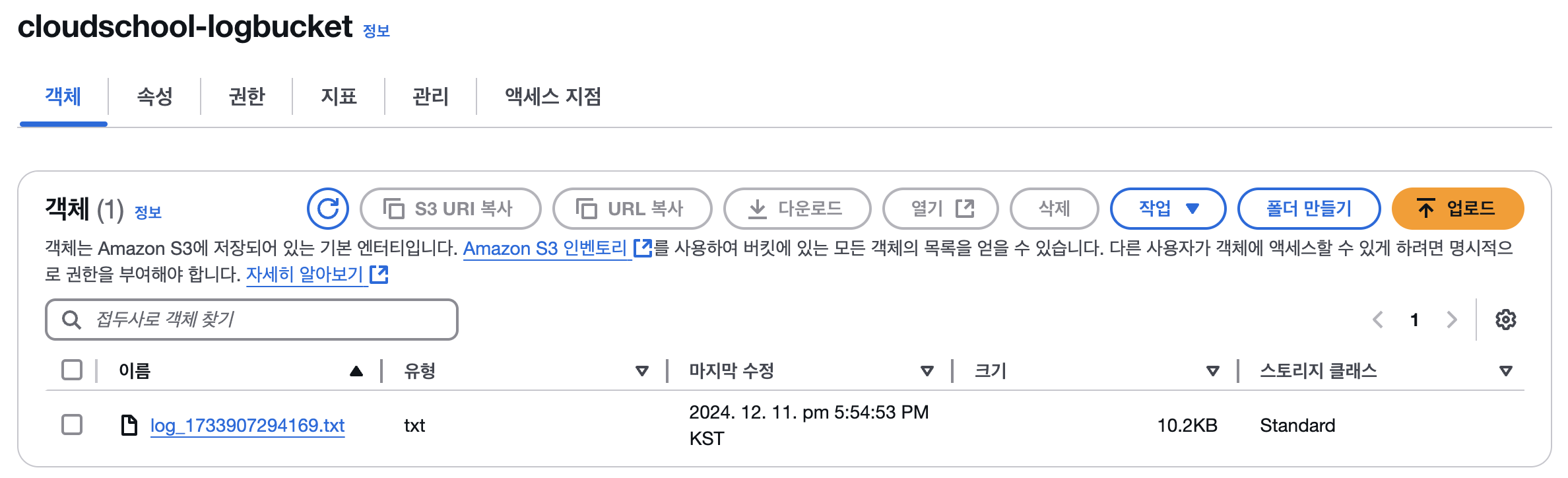
Kafka에서 메시지가 수신되면 S3에 로그 파일이 업로드된다.
S3 버킷에서 업로드된 파일을 확인할 수 있다.